












Research Finder
Find by Keyword
Did Deepseek destroy the NVIDIA moat? - PTX Vs CUDA
As the dust settles on the Deepseek R1 launch some fundamental elements of the innovation are starting to become apparent.

First off, apologies for the clickbait headline. As we look to digest the impact of the Deepseek R1 release the analyst community has scrambled to keep up with the news. Now we have some time to digest the impact of the Deepseek announcement some elements are becoming clear, well to me at least. The three key takeaways for me are - PTX Vs CUDA, Open Source and the Jevons paradox so lets dive into these three key areas;
PTX Vs CUDA
GPU computing involves several architectural layers. The hardware layer consists of the physical GPU components like CUDA cores, Tensor cores, RT cores, memory controllers, cache, and Streaming Multiprocessors. This is the physical silicon executing instructions. The microarchitecture layer encompasses the specific GPU architecture, such as NVIDIA's various generations (Fermi, Kepler, Maxwell, etc.), and the Instruction Set Architecture (ISA) defining the machine code, though this is usually abstracted from developers. Above this is the Intermediate Representation (IR) layer, where PTX (Parallel Thread Execution) resides. PTX is an assembly-like language acting as a bridge between high-level code and machine code. It allows code portability across GPU generations, as the NVIDIA driver performs Just-In-Time compilation from PTX to the machine code of the specific GPU. Developers rarely interact with PTX directly; it's generated by compilers.
The high-level programming layer features CUDA (Compute Unified Device Architecture), NVIDIA's platform and programming model. CUDA C/C++ extends standard C/C++ with GPU-specific features. It provides a high-level abstraction, simplifying GPU programming by offering an API, language extensions, and tools. CUDA code is compiled to PTX and then to the final executable. Finally, the application layer contains user applications, libraries, and frameworks like cuDNN, built upon CUDA and offering even higher-level abstractions for specialized tasks.
CUDA directly interfaces with developers, providing the programming model for GPU computing. CUDA code is compiled to PTX, which is then optimized and translated into machine code. PTX acts as the intermediate layer, ensuring compatibility across GPU architectures. It's not written by developers but is an output of compilers. The GPU driver compiles PTX into the final machine code, enabling runtime optimization and future hardware compatibility. CUDA provides the programming model, and PTX serves as the bridge between this code and the hardware, ensuring portability across NVIDIA GPUs.
An Instruction Set Architecture (ISA) is the fundamental interface between a computer's hardware and software. It defines the set of instructions a processor can execute, the data types it can manipulate, the registers it has available, how memory is organized and accessed, and how it handles interrupts. Essentially, the ISA is the language the hardware understands.
Think of it like this: if the hardware is the body of a computer, the ISA is its nervous system, dictating what actions it can perform. Programmers, whether writing in low-level assembly language or a higher-level language like C, ultimately work within the constraints and possibilities defined by the ISA. Assembly language instructions map almost directly to individual machine instructions defined by the ISA, giving programmers fine-grained control. C code, while more abstract, is compiled down to assembly or machine code that conforms to the ISA. The ISA dictates everything from how data is moved between registers and memory to how arithmetic operations are performed. It's the bedrock upon which all software is built.
The idea that DeepSeek's use of PTX breaks the CUDA "moat" misunderstands CUDA's role. CUDA is a high-level language simplifying GPU programming and widely used in production software. It allows for rapid development and access to optimized libraries. PTX, on the other hand, is a low-level, GPU assembly language enabling fine-grained optimizations, but it requires significant expertise and is tedious to work with. Think of CUDA as C and PTX as assembly. While PTX can offer performance gains, it's not something casually used. Optimizing from CUDA to PTX is common for deployed models needing that extra performance boost, but it's a specialized task, often targeting specific hardware.
DeepSeek's use of PTX isn't revolutionary; it's a standard practice for performance optimization. The real issue is the misleading headline, which implies DeepSeek's achievement lies solely in bypassing NVIDIA's proprietary language. This is incorrect, as both CUDA and PTX are NVIDIA proprietary technologies. PTX is already prevalent in optimized models. The headline oversimplifies the situation and ignores the nuances of GPU programming.
Why does this matter in the context of Deepseek? The Deepseek team probably due to export controls on the GPUs they could use had to innovate in a highly constrained environment. This led them to go deeper than most enterprises would and operate at the PTX layer. This would have been exponentially harder for the development teams, but ultimately led to the performance and cost savings that have been touted. Could other development teams do this? Of course, but would they want to? Without the same constraints around access to hardware the likelihood that developer will move away from CUDA and develop at the PTX layer is unlikely.
Why OpenSource Will Ultimately Win When It Comes To Models
Large Language Models (LLMs) like those from the GPT series, Gemini, and Grok have transformed how we interact with technology, offering capabilities in natural language processing for uses from text summarization to creative writing. They are versatile, aiding in education, accessibility, content creation, and even data analysis, while being scalable and efficient in handling large datasets. However, LLMs also bring challenges such as bias from training data, significant environmental impact, privacy risks, lack of transparency in decision-making, potential for misinformation, and job automation concerns. Ethically, there's a push towards transparent, fair AI development, with a focus on explainability and bias mitigation, alongside regulatory and educational efforts to ensure beneficial use. LLMs should be seen as tools that complement human abilities, with ongoing research essential for improving efficiency, ethics, and model interpretability.
Deepseek And The MIT Model
Bill Gurley recently posted on X about the different types of open source license models and as the industry looks to evaluate the various approaches it is worthwhile outlining what open-source means in the context of AI. Put simply open-source breaks down into three layers:
- Model
- Weights
- Training data
What we saw from Deepseek was the first time a model developer exposed both the model and the weights, and this should be applauded. Where concern still lies is that the Deepseek team didn’t expose the training data.
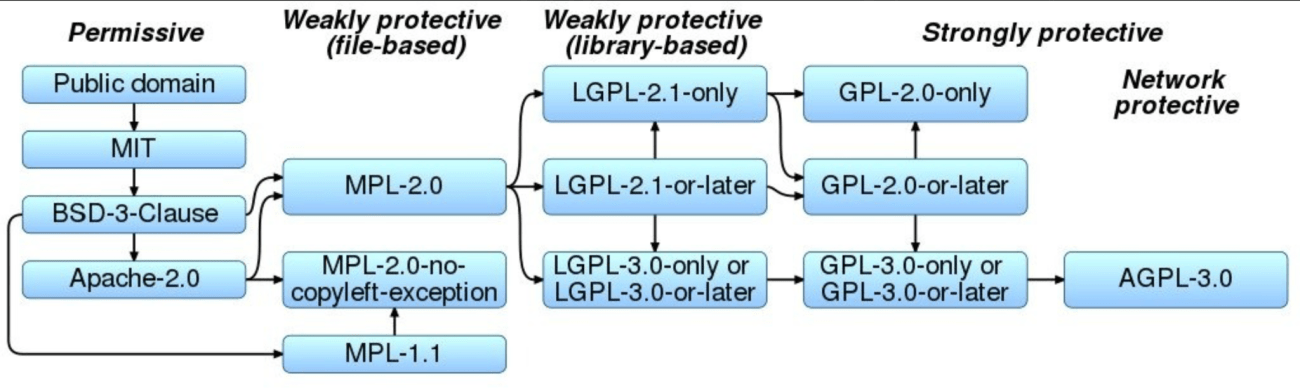
The MIT License is a popular open-source license known for its simplicity and permissiveness. It allows users to freely use, copy, modify, merge, publish, distribute, sublicense, and sell the software. The sole requirement is including the license and copyright notice in all copies or substantial portions of the software. It's highly compatible with other licenses, facilitating integration into projects with diverse licensing schemes, and the software is provided "as is," without any warranty.
Compared to other open-source licenses, the Apache License 2.0 shares similarities with the MIT License in its permissiveness and requirement for preserving copyright and license notices. It also grants patent rights, which the MIT License doesn't explicitly address. However, Apache 2.0 includes additional clauses regarding contributions, such as stating significant changes and a specific clause about trademark use. It's slightly more verbose but remains permissive. The GPL v3, in contrast, is copyleft, meaning derivative works must also be distributed under the GPL. This contrasts sharply with the MIT License, which doesn't impose such requirements. While GPL aims to keep software free, MIT allows proprietary use, potentially attracting commercial entities more readily. BSD licenses also offer comparisons. The 3-Clause BSD license is very similar to MIT but includes an additional clause about not using copyright holders' names for endorsement without permission. The 2-Clause BSD license is even closer to MIT, removing the endorsement clause and making it almost identical in permissiveness. The Creative ML OpenRAIL-M license, focused on AI, includes ethical usage guidelines to prevent misuse, unlike the MIT License's minimal restrictions.
In the AI context, models like GPT-2 were released under the MIT License, promoting wide accessibility for research and commercial use. However, some argue that not all MIT-licensed AI models are "truly open-source" if they don't release training data or weights. MIT-licensed models like Mistral 7B and Zephyr 7B have demonstrated competitive performance with fewer parameters than closed-source counterparts, offering a balance of capability and flexibility due to the license's permissiveness. The MIT License can foster a large community around a project due to its liberal nature, leading to more contributions, forks, and adaptations.
When comparing licenses in AI development, the MIT License doesn't mandate transparency in training data or model weights, which can be a limitation compared to licenses emphasizing this aspect for true open-source AI. Its permissiveness benefits commercial use, as companies can incorporate models into proprietary software easily. While the MIT License promotes innovation by reducing legal barriers, it may not directly address ethical concerns or misuse like some AI-specific licenses. The MIT License often results in broader community adoption but less control over how the technology is used or modified compared to stricter licenses. In conclusion, the MIT License is favored for its simplicity and permissiveness, making it attractive for developers and companies in AI who want to contribute to or use open-source models without stringent copyleft requirements or ethical stipulations. However, the lack of requirements for data transparency or ethical use means that while it fosters wide adoption and innovation, it might not align with all definitions or goals of open-source AI, particularly those emphasizing ethical deployment or data privacy.
We have already seen Sam Altman hint that OpenAI may change its perspective on open-source as an approach for their model development and the Deepseek developments will certainly have created pressure within Meta and the speed of innovation of Llama. TL;DR - Watch this space.
Jevons Paradox - What Does This Mean For The AI Trade?
You will have heard a lot about the ‘Jevons Paradox’ over the last few days as prominent Silicon Valley leaders have added the term to the lexicon of the AI landscape The Jevons Paradox, named after the economist William Stanley Jevons, is an economic theory stating that improvements in resource use efficiency can actually increase, not decrease, the consumption of that resource. Jevons observed this with coal in the 19th century, noting that as steam engines became more efficient, coal consumption in Britain rose because the lower energy cost expanded steam power's applications and demand. The core idea is that increased efficiency lowers the cost per unit of output, leading to more widespread use and higher total consumption. Jevons' historical example involved more efficient steam engines making steam power economical for more applications, thus increasing coal usage. Modern interpretations apply this paradox beyond energy resources to any situation where efficiency-driven increased demand stems from price elasticity or expanded use cases.
Regarding AI and GPU supply, as AI models become more efficient (requiring less computational power per task), the cost of AI operations decreases. This efficiency, achieved through better algorithms, data compression, or hardware advancements, can lead to broader AI adoption across industries, increasing overall AI computation demand. GPUs, crucial for AI, have also seen efficiency improvements. Newer architectures offer more performance per watt or dollar, theoretically reducing the need for GPUs for the same task. However, Jevons Paradox suggests that as GPUs become more efficient, the cost reduction enables more companies and individuals to deploy AI solutions, leading to a surge in GPU use. Efficiency gains also allow exploring AI in new domains or scaling existing applications, like more complex models or larger datasets. Thus, even if each AI task needs fewer GPUs or less energy, the total GPUs needed across all new and expanded AI applications can increase.
This increased GPU demand can strain supply chains, potentially leading to shortages or price increases, which in turn can spur further innovation and investment in GPU manufacturing. The paradox encourages investment in AI technology and hardware as the market sees potential growth, fueling the cycle of efficiency leading to demand. The introduction of more efficient models like DeepSeek-R1 has prompted questions about reduced demand for high-end GPUs. However, applying Jevons Paradox, analysts argue that these efficiency gains will increase overall computational resource demand, including GPUs. Industry sentiment, reflected in social media and analyst articles, often references Jevons Paradox when discussing AI efficiency's impact on GPU markets, suggesting that efficiency gains will likely result in more, not less, GPU usage.
While individual AI tasks might become less energy-intensive, the overall increase in AI applications can lead to higher total energy use, posing environmental challenges. The paradox can drive economic sectors, particularly tech sectors focused on AI and hardware, but also raises questions about resource allocation and sustainability. In conclusion, Jevons Paradox illustrates a counterintuitive outcome in the AI and GPU ecosystem where efficiency gains lead to higher demand rather than resource conservation. Understanding this is crucial for policymakers, investors, and tech companies to manage growth, investment, and environmental impact sustainably.
How do I summarize the Deepseek news and the level of innovation we are seeing and how it relates to the overall AI trade. A picture speaks a thousand words.

Looking Ahead
As DeepSeek challenges Silicon Valley's dominance through a focus on foundational research and open-source innovation we saw a violent shock to capital markets, with NVIDIA losing $600bn in one day - to put that in context, that is the same size as the entire mexican stock market. As I researched for this research Note a recent interview with DeepSeek CEO Liang Wenfeng stood out. The interview highlights how he prioritizes technical advancement over immediate profit, running DeepSeek like a research lab.
As DeepSeek triggers an AI price war, offering API access at a fraction of competitors' cost, while maintaining profitability through architectural innovation are we entering the first phase of commoditization? It's too early to say, but the first shots have certainly been fired.
As we reflect on the barrage of news and announcements a few key themes emerge for me; Enterprises want choice, so the Deepseek model was made rapidly available on the hyperscale cloud platforms. Read my coverage of the AWS Bedrock support here. Open source will win out - we have already seen 1,300+ forked versions of the Deepseek model emerge and one thing is certain, EVERY model development team will have spent the Monday after the new broke, reading up on what Deepseek were able to develop.
We live in interesting times, bring on next week.

Steven Dickens | CEO HyperFRAME Research
Regarded as a luminary at the intersection of technology and business transformation, Steven Dickens is the CEO and Principal Analyst at HyperFRAME Research.
Ranked consistently among the Top 10 Analysts by AR Insights and a contributor to Forbes, Steven's expert perspectives are sought after by tier one media outlets such as The Wall Street Journal and CNBC, and he is a regular on TV networks including the Schwab Network and Bloomberg.